This Mystery Photo Haunting Reddit Appears to Be Image Recognition Gone Very Weird

Look closer. (Rebrn)
Look at this thing. What is it? Just some kind of poorly drawn squirrel, right? Maybe a spread from an old suburbia-themed National Geographic that went through the wash?
Ok, look again, closer this time. This squirrel has a weird amount of eyes, yeah? And seems to be made at least partially of dogs? Check out its weird rear appendage, which is composed of slug tentacles that are themselves composed of birds. A two-headed fish lurks in the foreground, and upon reexamination the background is not mere swirls, but a warped, repetitive city, like a long lost Borges story illustrated by a hungover chalk artist.
What is going on?
Last week, this hellish magic eye popped up on Reddit with no attribution and the perfectly vague caption “this image was generated by a computer on its own.” It became an internet mystery, with guesses springing up across social networks. Reddit readers quickly pooled their human brains and attempted to parse this. Artists swapped thoughts with computer scientists. True believers clashed with skeptics. “It’s like what the mindset of a robot will look like,” said one user, while another announced, “I call f*ing mountains of steaming BULLSHIT.”

The way it should be. (Photo: Sebastian Wallroth/WikiCommons CC BY 3.0)
The most cogent theory came from user regregex, who, with syntactic tentativeness, ventured that it was a kind of exponential compilation, made up of image searches repeated ad infinitum. “The computer started with an image of a squirrel lying on a wooden rail… and then did a similar-image search on smaller and smaller parts of the image, blending in the top result each time,” he wrote. “But this is all off the top of my head.”
 The dog takeover has finally occurred. (Google Research Blog)
The dog takeover has finally occurred. (Google Research Blog)
The trail slowly cooled until this morning, when three engineers at Google Research Blog came out with the backstory. It turns out this skewed squirrel didn’t come from avant-garde computers making art on their own. It came from highly trained programs trying to recognize images, and running up against their own limits.
The programs in question are Artificial Neural Networks, or ANNs. ANNs work very differently from other programs. Instead of dividing problems into smaller and smaller subtasks, each of which is taken on by a different part of the program, all the parts of an ANN are connected into larger layers that work together and build on each other. If a traditional program is a well-oiled bureaucracy, an ANN is more like an idealized co-op—or a human brain. This makes them good at things that traditional programs can’t even attempt, like transcribing spoken words, or recognizing images.
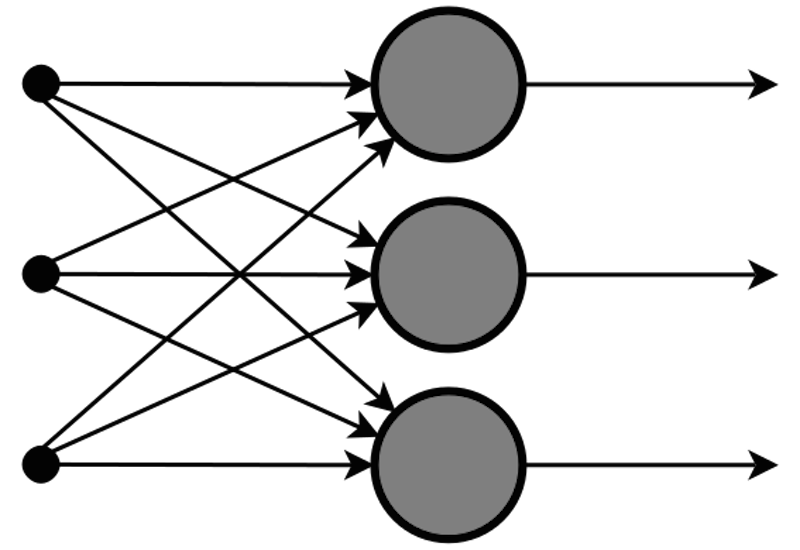
A very small part of an Artificial Neural Network. (Figure: Offnfopt/WikiCommons)
Because of their structure, ANNs learn by example. Imagine you want to teach an alien what a dog is, so you show him one—say, a cocker spaniel—and ask him to identify it. He has no idea, so he guesses randomly—”a tree?”—and then you give him the right answer (“no, a dog”). You repeat this process with all different kinds of dogs and not-dogs. For a while, he’s confused—what makes that chihuahua “dog” when the similarly-sized rat is not?—but after enough examples, he’s pretty good at telling you what is a dog and what isn’t. This is basically how ANNs work, too. Here’s how the Google researchers explain teaching their ANN to recognize a fork:
“We train networks by simply showing them many examples of what we want them to learn, hoping they extract the essence of the matter at hand (e.g., a fork needs a handle and 2-4 tines), and learn to ignore what doesn’t matter (a fork can be any shape, size, color or orientation).”
But what’s the best way to make sure the lesson is getting through? Maybe, after enough training, you ask the alien to draw a dog. The researchers decided to try with their ANNs, just for kicks.

ANNs try their hands at some simple objects. (Google Research Blog)
They had underestimated them. “Here’s one surprise,” they report. “Neural networks that were trained to discriminate between different kinds of images have quite a bit of the information needed to generate images too.”
As we’ve seen, the programs are far from robo-Renoirs. They’re more like Picasa Picassos—artists with no regard for spatial restraints who have learned about the world only through image searches. For example, this ANN was asked to draw a dumbbell, and here’s what it came up with:
 An ANN sort of gets a dumbbell right. (Google Research Blog)
An ANN sort of gets a dumbbell right. (Google Research Blog)
As the researchers say: “There are dumbbells in there alright, but it seems no picture of a dumbbell is complete without a muscular weightlifter there to lift them. In this case, the network failed to completely distill the essence of a dumbbell. Maybe it’s never been shown a dumbbell without an arm holding it.”
The researchers tried other tricks, too. Remember how ANNs are made of layers? In an image recognition ANN, each layer is responsible for looking at a certain aspect of a picture—edges and corners, say, or lines. Because every layer builds on the one below it, these aspects get more complex as you go through. The first layer has to find the edges for the middle layer to find the textures, and for the final layer to eventually find the whole dog.

There it is! (Google Research Blog)
It can be useful to know what each layer is getting up to. To figure this out, researchers employ a testing technique they call “Inceptionism”—effectively a department-by-department performance review, which separates the layers and asks them to each go down their own rabbit hole: “We ask the network: ‘Whatever you see there, I want more of it!’”
 Yes! More of that! (Google Research Blog)
Yes! More of that! (Google Research Blog)
Wonky things happen. The lower layers tended to “produce strokes or simple ornament-like patterns”—basically, the edges got edgier.

How an early neural layer thinks about these addaxes. (Photo: Zachi Evenor/Flickr/Google Research Blog)
Focusing on higher layers means even crazier results: “If a cloud looks a little bit like a bird, the network will make it look more like a bird. This in turn will make the network recognize the bird even more strongly on the next pass and so forth, until a highly detailed bird appears, seemingly out of nowhere.”

Stay tuned for a plane, and Superman. (Google Research Blogs)
Obviously this is fun—but we can go deeper! Keep asking the ANN to enhance what it sees in an image, and eventually it will turn everything into stuff it already knows. The result is, effectively, a memoryscape— a little history of everything the ANN has ever learned, smushed together into the framework you last gave it. Sheltered ANNs yearn for windows within windows. Architecture fiends find turrets in the sky. And an ANN who has spent its life gazing upon a lot of dogs, fish, and cityscapes might come up with something like that image at the top.
But one mystery remains—the original weird squirrel, uploaded to Reddit, is not among those in the photo set released by Google. Will the real computer please stand up?

Animal-trained ANNs see them everywhere. (Google Research Blog)
 A magical land. (Google Research Blog)
A magical land. (Google Research Blog) Seurat gets the ANN treatment. (George Seurat/Matthew McNaughton/Google Research Blog)
Seurat gets the ANN treatment. (George Seurat/Matthew McNaughton/Google Research Blog)
 Oh, that over there? That’s just Platypus Mountain. (Google Research Blog)
Oh, that over there? That’s just Platypus Mountain. (Google Research Blog)
A randomly generated “Neural Net Dream.” (Google Research Blog)
A Google ANN longs for apples. (Google Research Blog)
 More place-based Neural Net Dreams. (Google Research Blog)
More place-based Neural Net Dreams. (Google Research Blog)

A swirly ANN-generated landscape. (Google Research Blog)

Windows to nowhere. (Google Research Blog)





















{kind=link}
{kind=link}
Follow us on Twitter to get the latest on the world's hidden wonders.
Like us on Facebook to get the latest on the world's hidden wonders.
Follow us on Twitter Like us on Facebook